Sneakmeek
Technologies used: Python, Firebase, Typescript, Node.js, Express and React Native
As sneaker addict, I’m always trying to find the name of a sneaker I’ve seen outside.
I thought why not developing an app for it. So I pitched the idea to my friends, and we started working on it for fun.
The idea was to develop a mobile application that allows you to take a picture of a sneaker and find its name. We also had other features such as a market price tracker and upcoming sneaker releases.
We selected those three features for the MVP:
- Sneaker Brand Identification with Machine Learning
- Market Price tracker
- Upcoming sneaker releases
My friend Omid, the frontend expert, built up a fully functional React Native app in no time.
But the data part was a bit trickier because our classification model needed enough data to suggest a sneaker brand accurately. So we had to get some data.
Web Scraping
We decided to extract the data from SoleCollector, StockX and Goat. The minimum data points we needed for our model were: Image, Name, Price anything else was a bonus.
For SoleCollector and StockX, we used Python and Selenium to retrieve what we needed. The problem with browser automation is that your crawler no longer work when the layout of the page changes. But I managed to retrieve over 7.500 entries from StockX alone.
For the goat website, I reverse-engineered their API and found a way to directly access the data through Algolia because their API token was exposed in the query parameter of the HTTP request. Once that was found, I just consumed their API with Python.
The CSV file had over 30 columns and 26.000 lines including useful informations such as retail price and detailed brand informations.

At the end, we had over 40 GB of sneaker images and enough data to build a solid database.
We managed to build a simple classification model which suggests five sneakers that look like the sneaker in a given picture but we didn't go any further.
Upcoming sneaker releases
For the upcoming releases, I found a nice API that had information about the releases, the trendiest sneakers of the week with a scoring.
So I implemented a cronjob that retrieves the data weekly and feed it to a Cloud Firestore with Python.
I used free proxy IPs to avoid being flagged and exceed their rate limiting.
I had to implement a fallback strategy because most of the time the proxies are already used but I still want my cronjob to run.
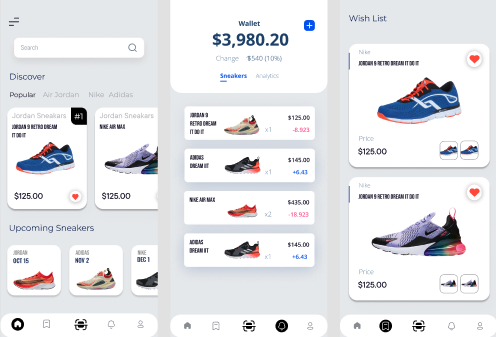
Market Price Tracker
This was the most difficult part of the project, yet the most interesting one. The challenge for a sneaker retail price is that they are no regulation.
The price of a sneaker can skyrocket due to a lot of different factors (hype before the release, limited edition, backed by famous artists, etc.) and most of the time the price only changes much after the release.
So we implemented an algorithm that retrieves as much retail price as possible from multiple sources (StockX, Google Shopping, etc.) for a given sneaker and then find the price that occurs the most with other parameters to get the right price. Because here we don't want to compute the mean of the different retail prices because it doesn't mean anything.
What are the next steps ?
We didn't had time to connect all the separate components together and we decided to pause the project to focus on Gaambay.
But I guess what could be interesting next would be to:
- Expose the market price service to use it (REST API?)
- Open source the sneaker dataset
- Create a Messenger bot that get the retail price of a sneaker
I'll probably continue working on it when I have more free time.
© Joseph-Emmanuel Banzio.RSS